












OUT OF YOUR HEAD – Part 4
In this last column of the series on spatial audio, I will be talking about my current Virtual Audio Processing System (VAPS).
My past experiences, as well as recent more advanced technology, has led me to conclude that a more modern approach to spatializing audio was needed. I had been using proprietary hardware with ad hock software, which was both inefficient and very costly. Since the time I assembled the first VAPS, technology has gotten much more advanced. Computer power has come a long way since the days of an Apple Mac II FX! With the advent of the Digital Audio Workstations (DAW) such as Pro Tools and the concept of plug-ins for audio processing, a new approach to spatial audio became possible. I decided to take the plunge and use new, “over the counter” software and hardware, and build a new
VAPS from the ground up.
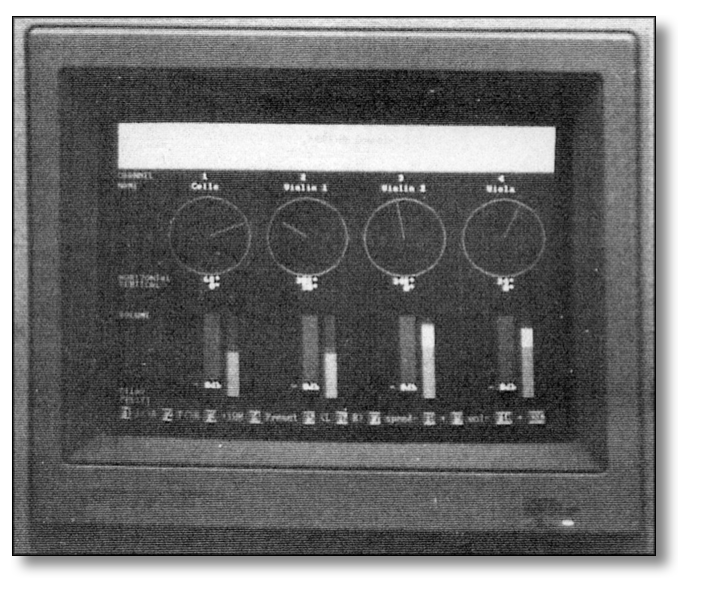
I wanted to take modern DAW software along with plug-ins and combine it with a powerful computer and make a much more cost effective and more efficient VAPS. I was also hoping to improve the overall accuracy of virtual acoustic environments. The original VAPS control software was a very basic 2D representation of a four channel mixing console. It consisted of a level meter, level control and a circular graphic for 360 degree panning per channel. It also had a master level control. That’s it! Very basic. The only other changeable parameter was the sample rate, which was 44.1 kHz and 48 kHz. The original VAPS had a very basic sequencer that required the user to input various locations in degrees along with time. It was a very slow and awkward way of creating automated location paths for audio source.
The first project was to investigate new software that may reflect more advanced 3D algorithms than what I had been using with the VAPS. There has been much work done around the world in laboratories and universities for creating more accurate head models (head related transfer function – HRTF). I was also looking for better, more advanced control software as well. I went on a search for the most advanced spatial audio software. The search turned up very little towards my goal. But, I came across a French company called Longcat 3D Audio Technologies. I heard a demo of their software called AudioStage and was very impressed with its spatial accuracy and its interface. I always imagined a 3D representation of rooms and the sound sources in those rooms. Longcat’s software interface had come very close to my vision. I got in contact with the company’s project manager Benjamin Bernard. Bernard was very knowledgeable, friendly and very helpful with all my questions. I found out that the Longcat team consisted of basically three people. Benjamin Bernard; 3D audio specialist, project manager & interaction designer: Clément Carron; 3D audio and graphic engines specialist – Interaction and application designer: and François Becker; Audio DSP and Computer Vision expert – Software architect and application designer.
I was very excited about their work and I soon purchased a basic Audiostage software package for me to begin my new VAPS project.
The first thing was to dive into the software and learn what everything does. I soon purchased their most advanced version of their application.
I will cover the basic areas of the AudioStage application, what it is and familiarized you as to what this powerful software can do.
AudioStage Application
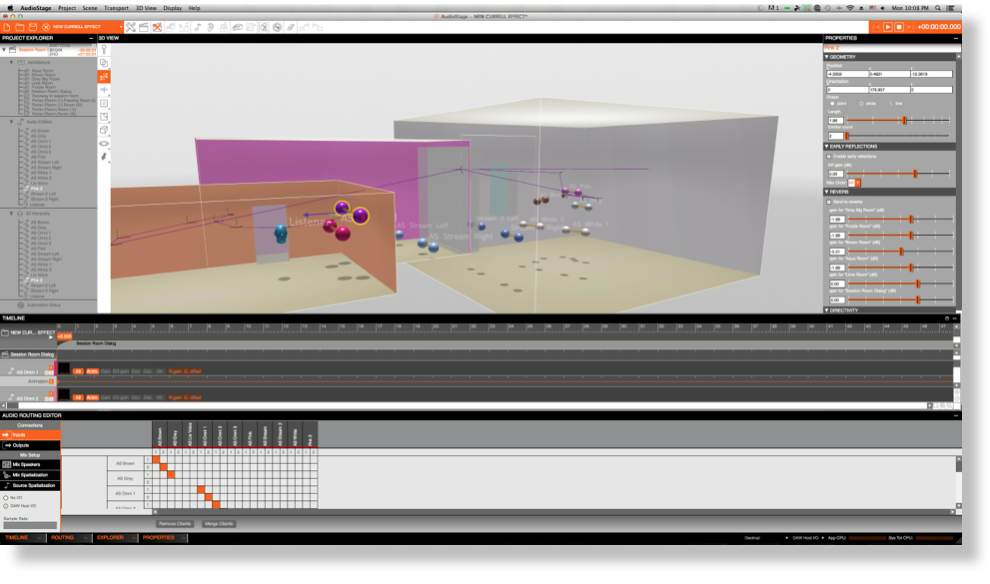
AudioStage is a 3D audio scene authoring tool that benefits from methods and techniques currently used in 3D image synthesis, and based on Longcat’s powerful 3D audio rendering and mixing engine named Kitten. It inserts seamlessly in DAWs (ProTools, Pyramix, Nuendo, Logic, etc.) and allows access to complex and dynamic audio mixing that is close to impossible to achieve with standard tools, such as a mixing desk. AudioStage is not an audio editing software per se, but is an application that runs in conjunction with one, using send and return plugins. AudioStage is based upon a number of hierarchical concepts and elements that make up a project. The software runs simultaneously in real-time with DAW editing software. It communicates (audio, timecode and transport commands) with the host DAW using AudioStage Track and Bus plugins, which are essentially standard audio plugins.
AudioStage Project
An AudioStage project contains one or more scenes, and defines one or more mixes. An AudioStage scene contains a number of audio sources and an environment (rooms, portals, etc.). Each scene has a begin time and an end time and follows some of the classical unities rules:
• unity of place: the AudioStage scene represents one physical space
• unity of time: the AudioStage scene has a linear time
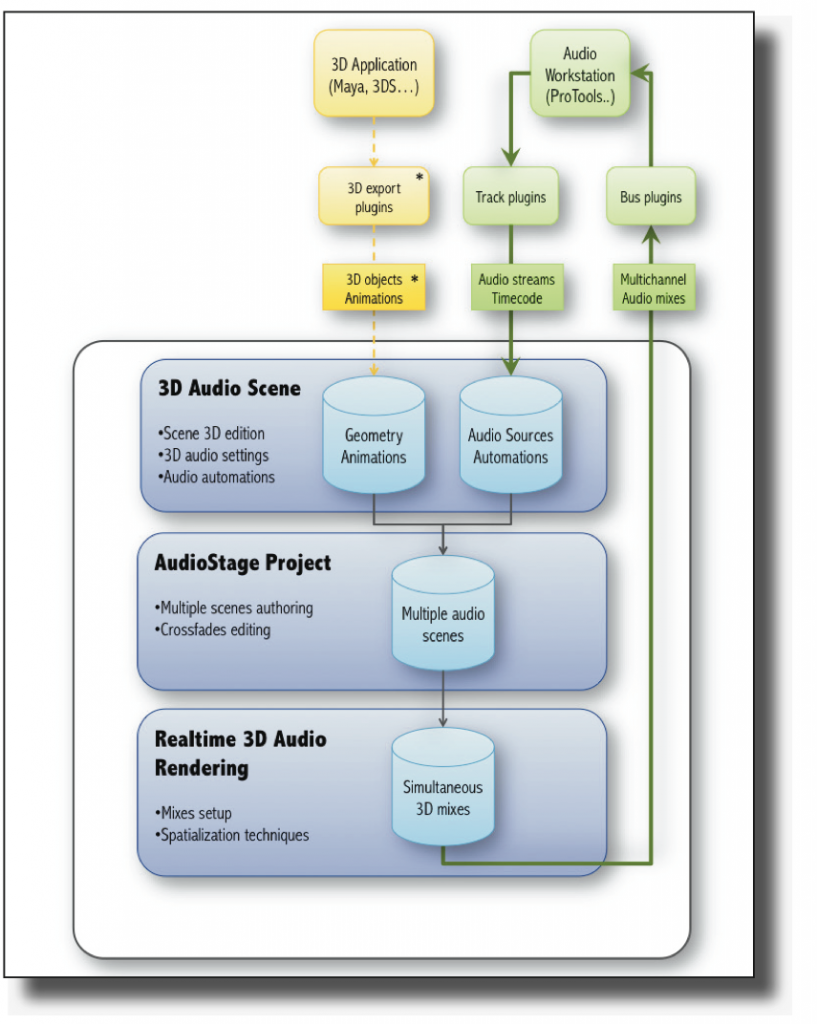
Any number of scenes can be chained up in a project. The environment can then be saved. The scene contains a number of audio sources. In AudioStage, the audio routing parameter routes AudioStage “track plugins” to the audio sources, for that particular scene. AudioStage “renders” in real-time the sequence of the scenes, using one or more simultaneous mixes. A mix is basically an output format that contains a given number of audio channels. It represents the support on which the audio is to be played back (headphones, stereo or 5.1, 7.1, 9.1, 10.1 loudspeakers, etc.). Each mix may contain one or more “panning laws”, called mix spatialization. The audio routing parameter routes the mix outputs back to the audio host, using AudioStage “bus plugins”.
The 3D Scene
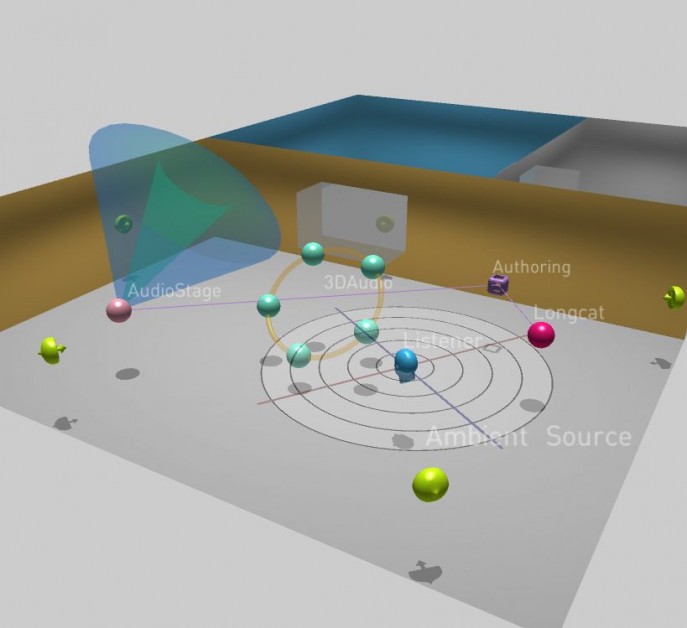
The 3D scene includes two layers of entities: 3D entities (sources, listeners, 3D groups, etc.) and architectural elements (rooms, portals).
An AudioStage scene may be compared to a movie scene: it has a start and end time, and it is displayed in the project explorer or in the timeline. All elements that constitute a scene only exist during the scene. You may create any number of scenes that can be chained in AudioStage. Each scene has particular architecture, routing and entities, and share the project’s global mix settings.
3D entities
3D entities correspond to punctual elements that are movable and animatable of the 3D scene. They logically include all elements that emit an audio signal (sources) or that receive it (listeners), but also 3D groups of these elements.

Audio sources
Audio sources are the signal emitting elements of the scene. They exist in two families in AudioStage: concrete sources that are freely movable in 3D, and ambient sources that are attached to rooms.
Concrete sources
Concrete sources are useful to represent a discriminable element of a scene (such as an actor, an object, etc.), they are defined by their spatial position, orientation, shape and number of emitters. They are mono emitters and punctual by default but may have up to 32 emitters that will fit in a linear or circular shape.
Ambient sources
Ambient sources are useful to playback distributed audio signals (such as multichannel ambient recordings or reverberation), they are systematically attached to a given room in the 3D scene. They are characterized by their orientation regarding the room, their number of emitters and their precise geometrical layout). They have no precise position and thus behave as infinitely placed sources, which explains their special representation on the room’s walls.
AudioStage allows a total of 256 emitters per scene.
Listeners
When a listener is inserted in the 3D scene, it corresponds to a listening point in the room. They receive audio signals from the various audio sources as well as the applied effects (reverb and reflections on walls) and produce a real-time mix of the former. It is possible to add multiple listeners to the same scene and to have simultaneous listening points in one mix.
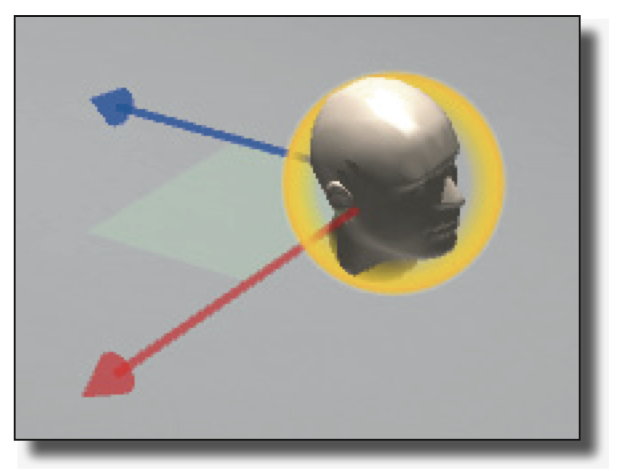
For example, you could have four listeners in a virtual room, one in each corner. The VAPS can output four separate stereo pairs, which represent four different perspectives of the virtual room. In the real world, four people with headphones could be positioned the same corners in a real room. Each person (listener) in the virtual room would have their own unique perspective of events, which correlate exactly with their physical position within the real room.AudioStage allows an unlimited number of listeners per scene.
3D Groups
3D Groups allow the user to link concrete entities together (concrete sources and listeners). A 3D Group may be added to another 3D Group in order to create complex hierarchies of entities that have different relative movements.
Architecture
As in the real world, AudioStage’s 3D audio scenes include sources (that emit sounds), listening points (that receive sounds), all of which are placed in an environment having acoustical properties: a propagation environment (air), solid surfaces (walls) and openings (portals), and closed spaces in which sound is reverberated (rooms).
Acoustical architecture is one of the main components of AudioStage: audio rendering is greatly impacted by the layout and the size of rooms, as well as the existence or not of openings between rooms.

In a nutshell, a room is a rectangular parallelepiped with six surfaces: ground, ceiling and four walls. Each surface has acoustical properties that dictate how it reflects sounds. Each room also has separate, specific reverberation settings.
Portals are openings created by the user between two adjacent rooms. A portal makes it possible to have acoustically communicating spaces, hence to hear a source that is situated in another room.
Automation
Automation gives the ability to program modifications of an audio parameter in time. Automations are displayed and edited in the timeline window. Automations can be used on the following components:
• mixes: master gain and gain offsets for other mixes
• rendering contexts: gain and offsets
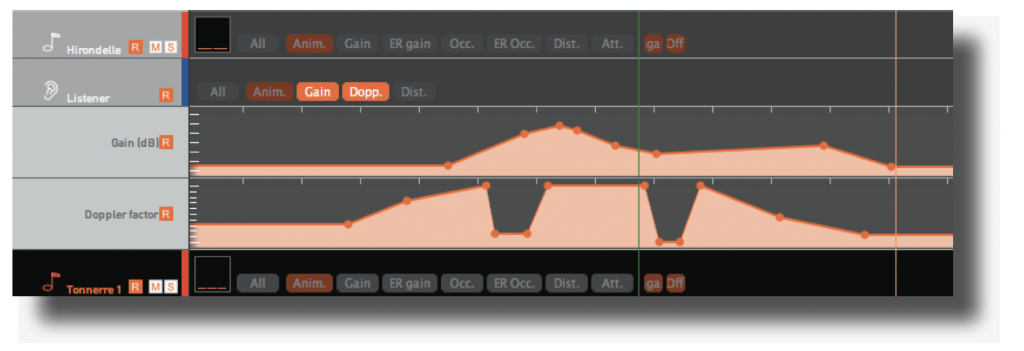
• sources: gain, gain offset for every mix and rendering context, ER (early reflections) gain, reverb gains, distance, attenuation, direct occlusion and ER occlusion factors
• listeners: gain, doppler and distance factors
• ambient sources: gain, gain offset per mix and per rendering context, reverb gains, distance, attenuation and direct occlusion factors
• automation groups: all the parameters mentioned above
Other parameters are solo, mute, automation read on/off and stereo audio level meters for each track. The automation in AudioStage is its weakest point. It uses a key-frame approach, which must be input and edited manually. There is no copy parameter for key-frames, which would save a lot of time when animating a scene. Also, it would be extremely useful to have an automation record function and then adjust the parameter being automated in real-time. This area of the software is a work in progress. The intention is to bring it up to par with the level of automation in other DAWS such as Pro Tools.
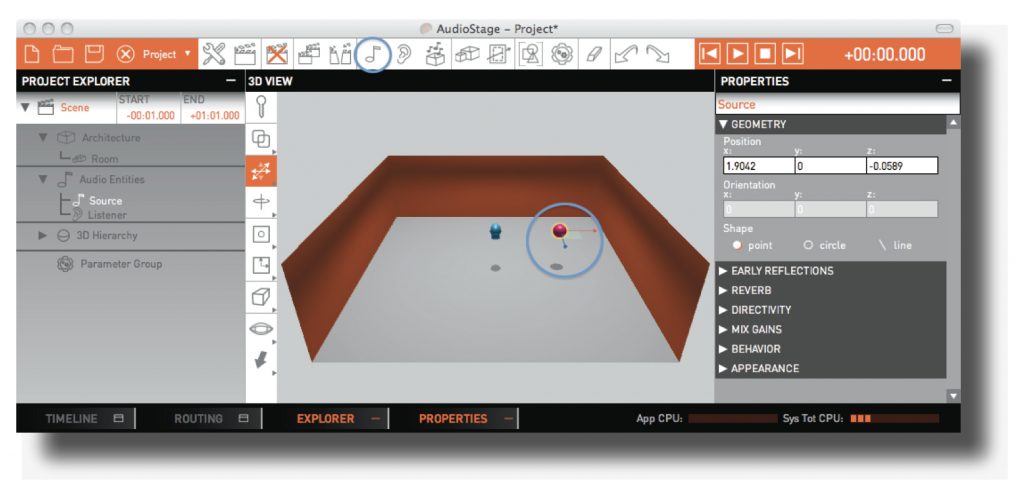
AudioStage Project Explorer The Project Explorer is a hierarchical view of the project: all scenes, rooms, 3D entities (sources and ambient sources, listener, 3D groups) and automation groups are displayed in the Explorer.
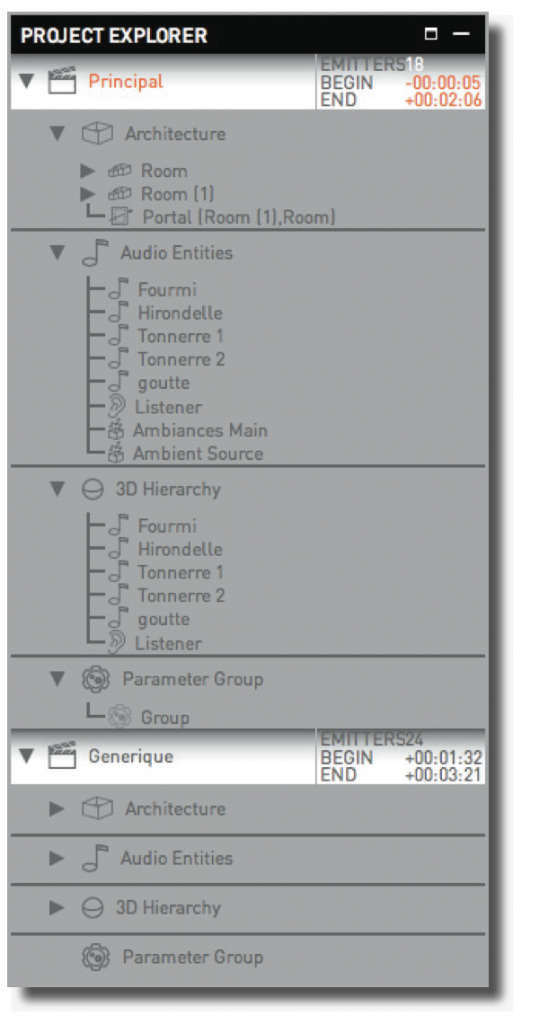
Scenes are listed in chronological order, the latter can be modified in the timeline. Each scene contains four groups:
• Architecture contains the rooms, portals and ambient sources of each scene.
• Audio entities includes all audio sources (normal or ambient)
• 3D hierarchy displays the 3D hierarchy of the scene, particularly if some sources belong to 3D groups.
• Parameter group lists the entities for which some parameters are shared.
The Project Explorer allows a direct selection of the project assets, the drag-dropping of some elements onto others (such as putting a source into a 3D group).
The scene’s entities may be renamed by double-clicking on the name. The total number of emitters is displayed for each scene.
Audio Routing
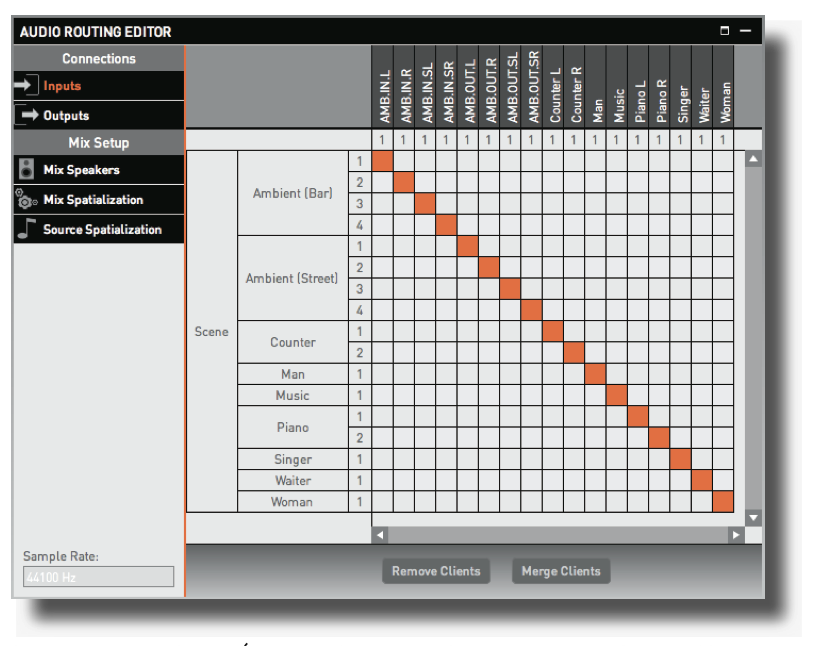
Audio routing is one of the main features of AudioStage.
The AudioStage principle is to run as a stand-alone application next to a VST/RTAS/AU host. Audio sources are fed by the host’s tracks (Cubase, ProTools, etc.), processed and mixed, and sent back to the host as mixes stems (stereo, multichannel, etc.). AudioStage plug-ins, named AudioStage Track and AudioStage Bus, allow data and transport communication between the host and AudioStage.
Audio routing allows, mostly:
• Inputs: to assign VST/RTAS/AU inputs to audio sources in AudioStage scenes.
• Outputs: to assign mixes outputs to VST/ RTAS/AU outputs.
• Mixes: to create and tune mixes based on the audio scene.
Input routing (e.g. the assignment of a client channel to a source emitter) is achieved by clicking on the corresponding box, whose color then turns orange. One will note that sources emitters only accept one input client channel at the time. On the contrary, one input client channel may be routed to any number of sources emitters.
Different AudioStage Clients may of course be routed to a single multi-emitter source, given that an emitter can only accept one client.
Properties Editor
This editor allows control over many aspects of the elements within the AudioStage 3D environment. There are many sub categories of editors within the properties editor. These include:
- Sources Properties Editor
- Ambient Sources Properties Editor
- Listeners Properties Editor
- Portals Properties Editor
- Rooms Properties Editor
- Scenes Properties Editor
- Portals Properties Editor
- Rooms Properties Editor
- Automation Group Properties Editor
10. 3D Group Properties Editor
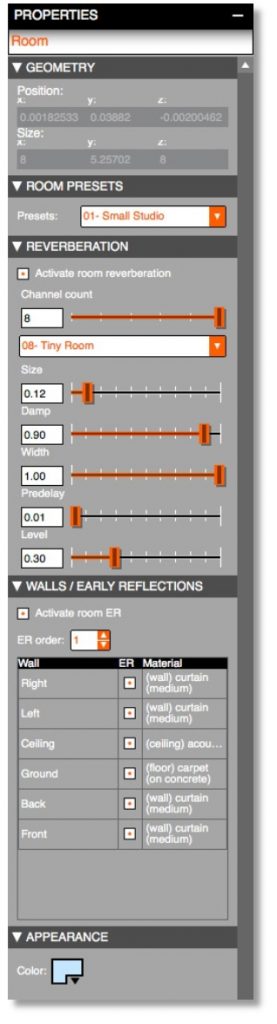
Using these properties editors, extensive control is possible over parameters such as:
Geometry: Displays the 3D position and orientation of the source, and allows to set the number of emitters for the source.
Reverb: AudioStage includes an internal reverberation processor. Reverberation is considered to be “diffused” (or emitted) by the walls of the room, as ambient sources are. The number of channels of the reverberation is adjustable (from 3 upwards): the greater the number of channels, the more homogeneous the density and distribution in space will be.
Early Reflections: The reflections on the walls are supported in AudioStage, and they are processed for each room. All the reflections are spatialized as audio sources are, which produces an excellent sensation of immersion in surround systems, S3D or H3D.
Materials: The sound reflected by walls is filtered differently, depending on the material the walls are made off. Presets of materials are available to adjust independently how each wall filters the sound it reflects.
By default, this setting is set to “Perfect Reflector,” which corresponds to a perfect acoustic mirror: the sound is reflected without being altered. Other available materials are classified by type (floor, wall, ceiling).
Directivity: These parameters set the directivity effects. This is very useful when a particular sound source shows a given directivity (for example a trumpet, a voice, etc.).
Behavior: These parameters manage the sonic behavior of the source in space.
• Direct Occlusion Factor sets the direct sound filtering in order to simulate an obstacle.
• Distance Factor sets a linear distance factor for the source, and modifies the source behavior in regard to attenuation, as soon as a portal is between the listener and the source.
• Distance Attenuation is a fine tuning of the logarithmic distance attenuation law, as soon as a portal is between the listener and the source.
Portals: This corresponds to the opening between two adjacent rooms. Like in the real world, they allow sounds to go from a room to another.
Group Automation: User controlled parameters to create audio automations that will affect every member of the group.
3D Groups: These are special entities in the 3D scene. They allow grouping of other 3D entities (sources, listeners, and even other 3D groups) and applies the same animation to all of them.
AudioStage Mixes
Several mixes can be defined in AudioStage that will be simultaneously carried out from the 3D audio scene. Each mix is defined by:
• a number of output channels (1 or more) called “speakers” in AudioStage, and that correspond to the real layout of the monitoring system (stereo, surround…)
• one or more “Rendering Contexts” (or “panning laws”), which are the spatialization processing applied to audio sources in the current mix.
Mix management interface
Mixes are created in the Audio Routing Editor. The “Mix” menu contains all the commands for mix creation and editing.
Mix management
It is possible to add, delete, open a mix preset and save the currently selected mix as a preset.
A number of mixes presets are bundled with AudioStage for the most common usage cases. Mix presets may also be created and saved by the user.
Master mix
When a project contains several mixes, it is more comfortable to work on a given reference mix and then adapt other mix settings according to their rendering specificities. The use of a master mix makes it possible to define a reference mix and then adapt it to each sound source from other mixes. Thus, if a source gain is modified in the master mix, the same modification will be applied in all other mixes. On the other hand, a gain offset set in an auxiliary mix will only have effect on the aux mix proper. It is also possible to define different gain offsets for rendering contexts that are contained in mixes. These offset parameters are defined in the Sources Properties Editor, and may be automated.
Speakers
Speakers (or loudspeakers) correspond to the real layout of the monitoring system on which the mix is to be played back, in regard to the audience.
The speakers’ position is relative to the sweet spot of the monitoring system, and includes the azimuth (angle in the horizontal plane) and the elevation (“height” angle of the loudspeaker in regard to the horizontal plane). Azimuth 0° is in front of the audience, azimuth +90° on the left side. Positive elevations are above the audience. For example, the standard layout for surround ITU 5.1 corresponds to five speakers, arranged at azimuths +30° (left channel), 0° (center channel), -30° (right channel), +/-110° (surround channels) in regard to the audience. Speakers positions are used by AudioStage to achieve a proper spatialization effect with most panning laws.
The addition of a speaker is done by setting its azimuthal position, and (if necessary) its elevation, then by clicking on the “Add Speaker” button. It is also possible to remove an existing speaker by selecting it and by clicking on the “Remove Speaker” button.
A special type of speaker is also possible, whose name is “not positioned”: it has no real specific position in space. This kind of speaker is useful (for example) for the bass channel (LFE), for a H3D rendering context (to be listened to on headphones) or for the stereo rendering context. Other rendering contexts need positioned speakers in order to achieve a proper spatialization effect.
Rendering Contexts
Rendering Contexts correspond to spatialization techniques available for a given mix. A mix may contain and simultaneously use one or several rendering contexts. The contexts that are present in a mix are specific to this mix and are not shared with other defined mixes.
Here are the various rendering contexts (formats) in AudioStage:
Mono
Mono is (as its name implies) a monophonic rendering of audio sources outputting on one channel. It may suit a mono mixing of a scene, or a bass channel for a multichannel mix.
Stereo
It’s a standard stereophonic rendering of the audio scene, that outputs on two channels. Speakers are considered as being arranged at +/-30°. Stereo may render a stereophonic mixing suited for headphones or loudspeakers. The panning law is the common equal-power law found on traditional mixing desks.
This context has a special setting that can be accessed. “Back Attenuation” makes it possible to gradually attenuate audio levels for sound sources located behind the listening point in order to favor a frontal attention (just like human hearing works). This phenomena is used in some downmix processors to automatically set the level of downmixed surround channels.
VBAP (Vector Base Amplitude Panning)
VBAP is an extension to the common stereo amplitude panning, to any number of loudspeakers.
A source can be panned in any loudspeaker 3D layout. VBAP therefore needs to know in advance the position of the monitoring system, and will use the three closest loudspeakers (this amounts to using a tessellation approach).
When using VBAP, at least three speakers need to be created and positioned in the mix.
H3D Stereo (“Headphones 3D Stereo”)
The binaural H3D stereo rendering creates an immersive 3D spatialization to be heard on headphones. This context needs an HRTF filter bank, of which a number are bundled with AudioStage. The H3D stereo context must be assigned to two speakers.
S3D Stereo (“Speakers 3D Stereo”)
The S3D Stereo rendering makes it possible to obtain an immersive 3D spatialization, which can be heard on two stereo speakers. Depending on the listening conditions, it is then possible to perceive sound sources coming from behind or in elevation, while the two speakers are placed in front of the audience.
The S3D Stereo context adapts itself to the opening angle of the two loudspeakers, which must be positioned in a symmetrical manner in regard to the audience. S3D also needs to use an HRTF bank for the spatialization (just like H3D). If assigned speakers are not positioned or not symmetrically placed, S3D won’t be able to work and a caution message will be displayed.
Ambisonic
The Ambisonics rendering places audio sources in space, using the Ambisonics technology. This rendering is limited to planar spatialization in this version, and outputs to four loudspeakers positioned in a square. The mix speakers layout is ignored in this version.
Source Spatialization
By default, every source will be rendered using all available contexts. It is possible to choose on a per source basis the context that will be used.
As an example in a surround mix, it would be possible to choose a S3D rendering for the “Voice” source, and a standard VBAP-surround rendering for the “Music” source. This setting is also possible for the reverberations.
That finishes up our overall basic view of the AudioStage software. In the next section, I will be giving a brief overview of the hardware (computer and audio) that I am using in conjunction with AudioStage and Pro Tools software. It is this overall combination of software and hardware that I call VAPS.
Longcat Audio Technologies:
Web – http://www.longcat.fr/
Facebook – https://www.facebook.com/longcataudio
Hardware
The hardware to run AudioStage and Pro Tools for the kind of projects I work on requires very high quality components as well as massive computer power.
I have been an Apple computer guy for a long time. I have eight Macintosh computers in my studio and one custom built PC but I needed a much faster computer than any that I already have.
After doing a lot of homework, I decided on buying the new MacPro…the one that looks like a trashcan.
The specifications are as follows:
Mac Pro
2.7GHz 12-core with 30MB of L3 cache – Turbo Boost up to 3.5 GHz
64GB (4x16GB) of 1866MHz DDR3 ECC
1TB PCIe-based flash storage
Dual AMD FirePro D700 GPUs with 6GB of GDDR5 VRAM each
Magic Trackpad
Two – Apple 27” Thunderbolt Displays
Apple Wireless Keyboard

In addition to the Mac Pro, I also need other audio hardware to complete the system. Here is a list of additional hardware:
Hard Disk Storage
Four – G -Technology Thunderbolt 4TB G-Drives (16 TB)
I find these drives very reliable, quiet and cool looking!
Amplifier
HeadAmp Special Addition Blue Hawaii
This amplifier is sonically very accurate. Great for mixing and sound design when it is critical to know exactly what you are hearing.

Woo Audio WES The WES amplifier is very musical with a very wide soundstage. The sound of this amplifier is very rich harmonically.

Headphone
Two -Stax SR 009 Electrostatic Headphones.
Quite possibly the finest headphone in the world. When processing audio in 3D, I only monitor through the Stax SR 009 Headphone.
Digital to Analog Converter
Antelope Zodiac+ with Voltikus power supply
I can playback audio files up to 24 bit 192 kHz sample rate.
Balanced analog XLR outputs feed the audio directly to the Blue Hawaii or the Woo Audio amplifiers.

Power Conditioning
PS Audio PerfectWave P3 Power Plant
The P3 takes in the old AC and outputs new, rebuilt power.
The results of feeding the equipment with rebuilt power is dramatic unrestrained dynamics even under the loudest passages, an open wide soundstage that does not collapse with volume and a naturalness to the music that is quite amazing.

Control Surface
Avid Artist Series control surfaces for hands on control for all the software applications.
MC Control
MC Transport
MC Mix

VAPS Hardware Control Workstation

VAPS Audio Playback System

Conclusion
This new VAPS is in all ways better than the original VAPS. I suppose I could call this new version VAPS2 and the original VAPS1. I find the accuracy of the VAPS2 head models (HRTFs) to be at least as good as the VAPS1. But AudioStage includes many different HRTFs so depending on the application, there is far more flexibility. In contrast, VAPS1 had only one HRTF set. The AudioStage interface and control software is light years beyond VAPS1. I have radically more control over each sound source with the VAPS2.
The New MacPro computer running AudioStage and Pro Tools is also radically more powerful than the VAPS1, which was a Mac II FX!! VAPS1 could only run 4 3D processed audio channels in real-time. VAPS2 can run up to 128 3D processed audio channels in real-time!
The VAPS2 audio playback system is much higher quality and much more accurate than VAPS1. The VAPS1 headphone was also STAX but the SR 009 is a much much better headphone.
In addition to my comment earlier about the AudioStage automation lacking important features, I also would like to see the ability to create 3D graphic objects that can be placed into the environments to which “audio texture maps” could be applied to create different reflection and absorption characteristics. I think this ability could add to the accuracy of the virtual audio soundscape.
In case you are curious, the cost of the entire VAPS2 was approximately $50,000. The VAPS1 set me back about $500,000! Technology has come a long way in 28 years!
So to what end am I using such a sophisticated and costly system? I will talk about it next month but here is a hint. I have created a specially processed audio file that when heard on the VAPS2 audio playback system, can literally connect the listener to the universe! This process is called “Harmonic Resonance of the Quantum Potential”.
See you next month here at the Event Horizon!
You can check out my various activities at these links:
http://transformation.ishwish.net
http://currelleffect.ishwish.net
http://www.ishwish.net
http://www.audiocybernetics.com
http://ishwish.blog131.fc2.com
http://magnatune.com/artists/ishwish
http://www.plenumvoid.com
Or…just type my name Christopher Currell into your browser.
Current Headphone System: Woo Audio WES amplifier with all available options, Headamp Blue Hawaii with ALPS RK50, two Stax SR-009 electrostatic headphones, Antelope Audio Zodiac+mastering DAC with Voltikus PSU, PS Audio PerfectWave P3 Power Plant. Also Wireworld USB cable and custom audio cable by Woo Audio. MacMini audio server with iPad wireless interface.
Want to join discussion?
Feel free to contribute!